The dataset of this case study is the Kaggle's most famous bank customer churn
dataset. This is a very good dataset because it includes numeric columns with discrete and continuous numbers, categorical columns with 2
categories and 3 categories. To start, We need to import the packages first.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
After get all the packages ready, we can now use Panda's read_csv function to
read the dataset.
df = pd.read_csv ("churn.csv")
print(df.head())
Null values and duplicated values need to be removed before build the model.
Replace NA with mean() or simply drop them if there aren't many of them. Remove the duplicated values if exist. We also need to drop some
columns if they are not useful for the prediction.
In statistics, Outliers are data points that are far from other data points
and they can distort statistical results.Thus outliers are bad for predictions. Although for classification trees, Like this case, removing
outliers might not be necessary. But the best practice is to remove them in case they unduly influence the model's performance. Checking
the outliers in categorical columns and numeric columns are different. For categorical columns, handling infrequent categories is needed.
Decision trees, especially if using a basic algorithm, can be sensitive to rare categories. Removing or combining infrequent categories
might help prevent the tree from creating specialized branches for these rare occurrences. Let's go back to our dataset.
print(df['Geography'].value_counts())
print(df['Gender'].value_counts())
# The results are:
France 5014
Germany 2509
Spain 2477
Name: Geography, dtype: int64
Male 5457
Female 4543
Name: Gender, dtype: int64
From the output, it is safe to say there are no infrequent categories. For the
numeric columns, We can first use Panda's describe function to have a brief look. Boxplot is a another good way to have them visualized.
print(df.describe())
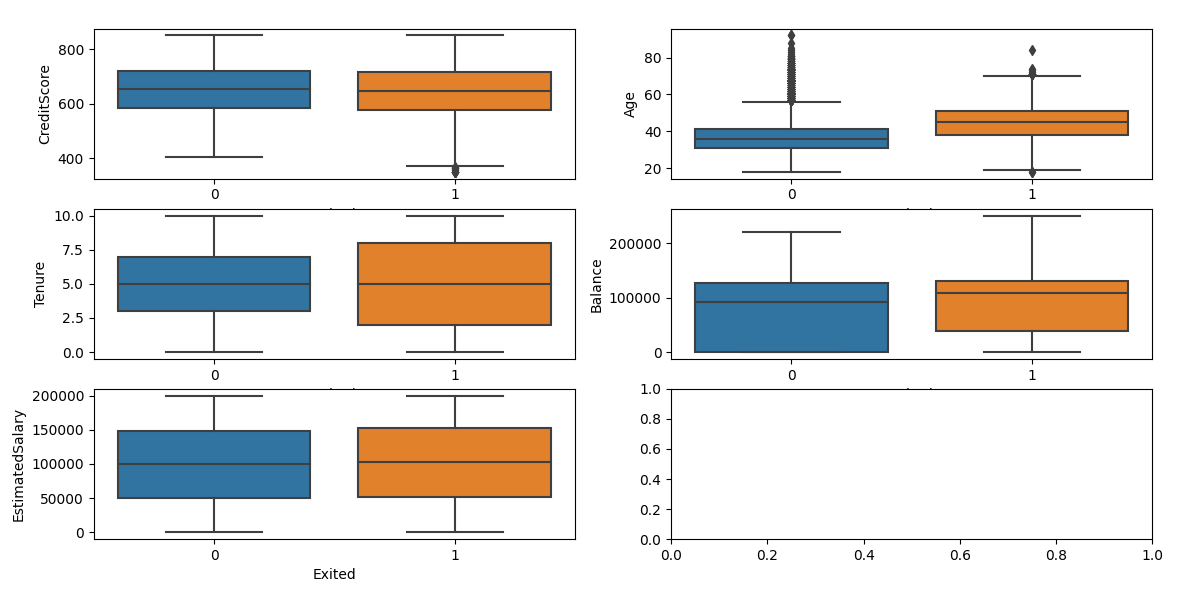
fig, ax = plt.subplots(3,2, figsize = (15,15))
for i, subplot in zip(numcols, ax.flatten()):
sns.boxplot(x = 'Exited', y = i , data = df, ax = subplot)
plt.show()
From the images, we can see there are some outliers in some columns. We now use
Inter Quartile Range (IQR) to remove outliers.
The next step is to transform categorical labels to numerical labels.
For category columns with 2 options, we just use get_dummies function to change the categories to 1 or 0. For Geography column, because it
has 3 categories, we can use the same function to change it to 3 separate columns without drop the first category. Some articles use LabelEncoder
but it might cause ordinal problem so it is not recommended.
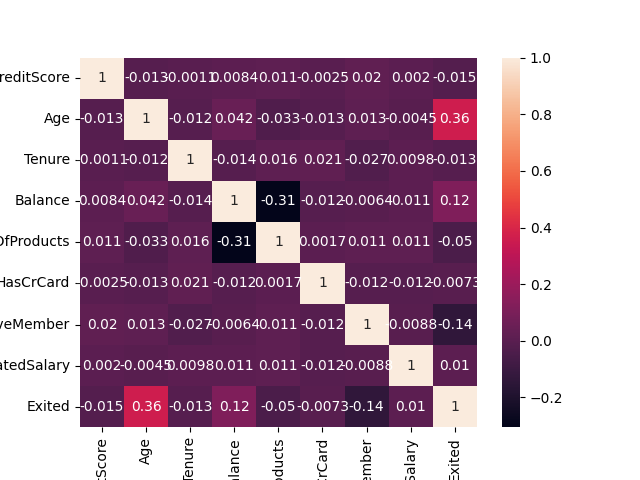
Correlated features is another problem we have to deal with during preprocessing.
Using Panda's Corr function and heatmaps plot we can determine features' dependency on other features and the target variable.it is safe to say you have
at least 0.6 (or -0.6) to call it a good correlation. The result below tells us that the features and target variable are not well correlated.
correlation= df.corr()
sns.heatmap(correlation,annot=True)
plt.show()
We have finally finished the preprocessing and start the model building
stage.Tuning the parameters helps improve the accuracy.
dt = DecisionTreeClassifier()
X = df.drop('Exited', axis= 1)
y = df['Exited']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state= 42)